Best Practices for Data Cleaning and Preprocessing
As data scientists, we often find ourselves immersed in a vast sea of data, trying to extract valuable insights and hidden patterns. However, before we embark on the journey of data analysis and modeling, we must first navigate the crucial steps of data cleaning and preprocessing. In this blog post, we will explore the significance of data cleaning and preprocessing in data science workflows and provide practical tips and techniques to handle missing data, outliers, and data inconsistencies effectively.
Why Data Cleaning and Preprocessing Matter?
Data cleaning and preprocessing are fundamental steps in the data science process. High-quality data is essential for accurate analysis and modeling.
Improved Accuracy: Incomplete data can lead to biased results and inaccurate models.
Better Insights: Preprocessed data reveals more profound insights, patterns, and trends. Removing noise allows us to focus on the meaningful aspects of the data.
Model Performance: Machine learning models rely on clean data.
In this blog, we’ll embark on a journey of data processing with the R programming language. To navigate this journey, the {tidyverse} package, a powerhouse of interconnected tools, will allow us to efficiently examine our data. Let’s dive into the world of R and witness the magic of turning raw data into meaningful insights.
- Load in the Required Packages
# Install and load the tidyverse package
install.packages("tidyverse")
library(tidyverse)
library(janitor)
- Create or load your data
df_1 <- tibble(
id = 1:5,
name = c("Alice", "Bob", "Amber", "Fred", "Eve"),
Age = c(25, 31, NA, 23, NA),
gender = c("Female", "Male", NA, "Male", "Female"),
Score = c(80, 91, 87, 77, NA)
)
df_2 <- tibble(
id = 6:7,
name = c("Jenny", "Dave"),
Age = c(29, 11),
gender = c("Female", "Male"),
Score = c(40, 70)
)
df_1
## # A tibble: 5 × 5
## id name Age gender Score
## <int> <chr> <dbl> <chr> <dbl>
## 1 1 Alice 25 Female 80
## 2 2 Bob 31 Male 91
## 3 3 Amber NA <NA> 87
## 4 4 Fred 23 Male 77
## 5 5 Eve NA Female NA
df_2
## # A tibble: 2 × 5
## id name Age gender Score
## <int> <chr> <dbl> <chr> <dbl>
## 1 6 Jenny 29 Female 40
## 2 7 Dave 11 Male 70
Addressing Data Inconsistencies:
Suppose the dataset combines data from different sources, which are stored differently. We can standardise these inconsistencies as follows:
- Data Standardisation: We can standardise the names to follow a consistent format. For example below, the column names “Age” and “Score” have been standardised to “age” and “score” in the dataframe. This lowercase naming convention is consistent with the other column names.
df_1 <- clean_names(df_1)
df_2 <- clean_names(df_2)
df_1
## # A tibble: 5 × 5
## id name age gender score
## <int> <chr> <dbl> <chr> <dbl>
## 1 1 Alice 25 Female 80
## 2 2 Bob 31 Male 91
## 3 3 Amber NA <NA> 87
## 4 4 Fred 23 Male 77
## 5 5 Eve NA Female NA
df_2
## # A tibble: 2 × 5
## id name age gender score
## <int> <chr> <dbl> <chr> <dbl>
## 1 6 Jenny 29 Female 40
## 2 7 Dave 11 Male 70
- Data Integration: When combining data from multiple sources, ensure that all data fields align correctly.
Let’s combine the data frames df_1 and df_2 vertically by stacking
their rows on top of each other to create a unified data frame, df.
df <- bind_rows(df_1, df_2)
df
## # A tibble: 7 × 5
## id name age gender score
## <int> <chr> <dbl> <chr> <dbl>
## 1 1 Alice 25 Female 80
## 2 2 Bob 31 Male 91
## 3 3 Amber NA <NA> 87
## 4 4 Fred 23 Male 77
## 5 5 Eve NA Female NA
## 6 6 Jenny 29 Female 40
## 7 7 Dave 11 Male 70
Managing Outliers:
Let’s assume that there are some extreme outliers in the dataset. We can deal with outliers as follows:
- Visual Inspection: Plotting a scatter plot may reveal outliers as data points far away from the general trend. We can visually inspect these data points and decide how to deal with them. Deletion of outliers is only recommended when the data point is seen as a data-entry mistake, rather than unusual. However, getting the record corrected would be a better solution!
ggplot(df, aes(x = age, y = score)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(title = "Scatter Plot of Age vs. Score",
x = "Age", y = "Score")
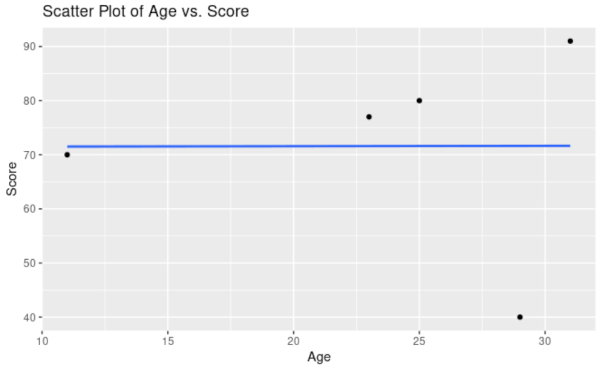
We see that there is one potential outlier. Typically, Score increases with Age, but Jenny’s score is very low, given her age.
Handling Missing Data:
Missing data is a common challenge in real-world datasets. Ignoring missing values or handling them poorly can lead to skewed conclusions. Some methods of handling missing data are:
Deletion: Remove rows or columns with missing values. This should only be done when the “missing-ness” is not related to the outcome of interest.
Imputation: Replace missing values with statistical measures such as the mean, median, or mode.
Advanced Techniques: Machine learning-based imputation methods, like K-nearest neighbors (KNN) or regression imputation, can be used for more accurate filling of missing values. This is the gold standard for imputation methods, and is most likely to reduce the bias in our models and findings.
Below are some common techniques for handling missing data. Here, missing data is addressed using mean and median imputation, replacing gaps in ‘age’, ‘score’, and ‘gender’ columns with appropriate measures. Subsequently, categorical variables are converted to factors and integers to ensure accurate analysis. The code also showcases advanced transformations such as encoding categorical variables as binary features and performing data splitting for machine learning models.
df <- df %>%
mutate(age = replace_na(age, mean(age, na.rm = TRUE)),
score = replace_na(score, median(score, na.rm = TRUE)),
gender = replace_na(gender, "Unknown"))
df
## # A tibble: 7 × 5
## id name age gender score
## <int> <chr> <dbl> <chr> <dbl>
## 1 1 Alice 25 Female 80
## 2 2 Bob 31 Male 91
## 3 3 Amber 23.8 Unknown 87
## 4 4 Fred 23 Male 77
## 5 5 Eve 23.8 Female 78.5
## 6 6 Jenny 29 Female 40
## 7 7 Dave 11 Male 70
Let’s explore some data cleaning and processing steps using the {tidyverse} package. The {tidyverse} package is an umbrella package; it imports useful packages for us. The ones we rely on below are {dplyr} and {tidyr}. Now let’s begin:
When working with data in R, it’s important to ensure that the data is
in the right format for analysis and visualisation. Factors are data
types in R that are used to represent categorical variables. Let’s
convert the gender column to a factor and the age column to an
integer. By converting the gender column to a factor, we’re telling R
that the variable is categorical and has a limited set of possible
values. Factors also help ensure that the data is treated correctly in
statistical analyses and modeling.
df <- df %>%
mutate(gender = as.factor(gender),
age = as.integer(age))
df
## # A tibble: 7 × 5
## id name age gender score
## <int> <chr> <int> <fct> <dbl>
## 1 1 Alice 25 Female 80
## 2 2 Bob 31 Male 91
## 3 3 Amber 23 Unknown 87
## 4 4 Fred 23 Male 77
## 5 5 Eve 23 Female 78.5
## 6 6 Jenny 29 Female 40
## 7 7 Dave 11 Male 70
- Encoding Categorical Variables
Many models don’t work with factors (categorical variables) straight out of the box. A simple workaround is to convert factors to a series of binary variables:
df_encoded <- df %>%
mutate(is_female = as.numeric(gender == "Female"))
df_encoded
## # A tibble: 7 × 6
## id name age gender score is_female
## <int> <chr> <int> <fct> <dbl> <dbl>
## 1 1 Alice 25 Female 80 1
## 2 2 Bob 31 Male 91 0
## 3 3 Amber 23 Unknown 87 0
## 4 4 Fred 23 Male 77 0
## 5 5 Eve 23 Female 78.5 1
## 6 6 Jenny 29 Female 40 1
## 7 7 Dave 11 Male 70 0
- Data Transformation
Sometimes our models work better with transformed data. For example, if the distribution of a feature is highly skewed, a log or square root transform can improve the symmetry of its distribution:
# Apply square root transformation to age
df_encoded <- df_encoded %>%
mutate(sqrt_age = sqrt(age))
df_encoded
## # A tibble: 7 × 7
## id name age gender score is_female sqrt_age
## <int> <chr> <int> <fct> <dbl> <dbl> <dbl>
## 1 1 Alice 25 Female 80 1 5
## 2 2 Bob 31 Male 91 0 5.57
## 3 3 Amber 23 Unknown 87 0 4.80
## 4 4 Fred 23 Male 77 0 4.80
## 5 5 Eve 23 Female 78.5 1 4.80
## 6 6 Jenny 29 Female 40 1 5.39
## 7 7 Dave 11 Male 70 0 3.32
- Feature Engineering
Feature engineering is just making new columns from old ones. For example, score per age could be found as:
# Create new feature: score_per_age
df_encoded <- df_encoded %>%
mutate(score_per_age = score / age)
df_encoded
## # A tibble: 7 × 8
## id name age gender score is_female sqrt_age score_per_age
## <int> <chr> <int> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 1 Alice 25 Female 80 1 5 3.2
## 2 2 Bob 31 Male 91 0 5.57 2.94
## 3 3 Amber 23 Unknown 87 0 4.80 3.78
## 4 4 Fred 23 Male 77 0 4.80 3.35
## 5 5 Eve 23 Female 78.5 1 4.80 3.41
## 6 6 Jenny 29 Female 40 1 5.39 1.38
## 7 7 Dave 11 Male 70 0 3.32 6.36
- Data Splitting
This is an essential step for many machine learning models; we split the data into a training set to train the model on, and a test set to allow us to test model predictions. The tidymodels package offers a consistent and streamlined approach to data splitting and other aspects of modeling workflows, making it a powerful tool for data scientists.
# Install and load the tidymodels package
install.packages("tidymodels")
library(tidymodels)
# Create a split index using initial_split
split_data <- initial_split(df_encoded, prop = 0.5)
split_data
## <Training/Testing/Total>
## <3/4/7>
# Extract the training and testing data sets
train_data <- training(split_data)
test_data <- testing(split_data)
train_data
## # A tibble: 3 × 8
## id name age gender score is_female sqrt_age score_per_age
## <int> <chr> <int> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 6 Jenny 29 Female 40 1 5.39 1.38
## 2 5 Eve 23 Female 78.5 1 4.80 3.41
## 3 7 Dave 11 Male 70 0 3.32 6.36
test_data
## # A tibble: 4 × 8
## id name age gender score is_female sqrt_age score_per_age
## <int> <chr> <int> <fct> <dbl> <dbl> <dbl> <dbl>
## 1 1 Alice 25 Female 80 1 5 3.2
## 2 2 Bob 31 Male 91 0 5.57 2.94
## 3 3 Amber 23 Unknown 87 0 4.80 3.78
## 4 4 Fred 23 Male 77 0 4.80 3.35
We use the initial_split() function to split the data_encoded
dataframe into training and testing sets. The prop specifies the
proportion of data to allocate for the training set. In this case, we’ve
gone for a 50:50 split. The training() and testing() functions are
then used to extract the training and testing data sets.
Advanced Data Cleaning and Processing Techniques
Data cleaning and preprocessing have evolved beyond the traditional methods. Advanced techniques such as Time-Series Imputation and Deep Learning-Based Outlier Detection can handle complex scenarios and yield more accurate results:
Time-Series Imputation: Missing values can disrupt patterns. Techniques like forward-fill, backward-fill, or using the last observation carried forward can be effective.
Deep Learning-Based Outlier Detection: Autoencoders can identify subtle outliers in high-dimensional data.
Deeper Dive into Feature Engineering:
Feature engineering goes beyond data cleaning — it’s about creating new attributes to improve model performance, for example:
Polynomial Features: Transforming features into higher-degree polynomials can capture non-linear relationships.
Interaction Features: Multiplying or combining features can reveal interactions between them.
Advanced data cleaning steps involve more specialised techniques that can help you handle complex scenarios. Here are some references and resources that provide in-depth information on advanced data cleaning techniques:
Automation and Tools:
For R users, the journey of data cleaning and preprocessing becomes even more seamless due to powerful libraries and tools tailored to your needs. The {tidyverse} suite of packages offers {dplyr} for efficient data manipulation, {tidyr} for tidying up messy datasets, and {stringr} for handling text data, among others. Whether it’s imputing missing values, encoding categorical variables, or standardising features, R’s automation libraries such as {tidyverse} empower you to focus on extracting insights rather than getting caught up in manual data cleaning tasks. With these tools by your side, you can navigate the data preprocessing landscape with confidence and efficiency.
In conclusion, data cleaning and preprocessing are essential steps that pave the way for accurate analysis and reliable insights. By following the best practices outlined in this blog post, you can ensure that your data is well-prepared for modeling and analysis.
By addressing missing values, outliers, and inconsistencies, you’re laying a strong foundation for impactful data-driven decision-making. As you delve into more advanced techniques, explore feature engineering, and embrace automation, you’ll unlock even more potential from your data. So, whether you’re a data scientist, researcher, or business professional, embracing these practices will undoubtedly contribute to the success of your data-driven endeavours.
Remember that the effort invested in cleaning and preprocessing data is an investment in the quality of your results.
Happy data cleaning and preprocessing!